在办公场景中,PDF 转 Word 是高频需求,但转换后出现乱码却让人头疼。那么pdf转word乱码怎么办呢?本文结合技术原理与实战经验,提供一套系统化解决方案,帮你快速修复乱码问题。
一、乱码根源:3 大核心成因解析
1. 字体缺失或不兼容(占比 60%)
- 技术原理:PDF 嵌入的特殊字体(如方正粗雅宋、汉仪菱心体)未被转换工具识别,导致 Word 用默认字体(如宋体、Times New Roman)强行替换,出现符号错位(如「¥」变「Y」)或方块乱码(□)。
- 典型场景:政府公文、设计稿 PDF(含企业定制字体)、古籍扫描件(手写体 OCR 识别误差)。
2. 编码格式冲突(占比 25%)
- 常见错误:PDF 使用 GBK 编码,转换工具默认 UTF-8 解析,导致中文字符二进制码错位(如「你」的 GBK 编码 B0A5 被解析为 UTF-8 的两个字符)。
- 隐藏风险:扫描件 OCR 生成的伪文本 PDF(实际为图片层 + 不可见乱码文本),转换时触发「图文层叠加错误」。
3. 复杂格式解析失败(占比 15%)
- 布局陷阱:多栏排版、嵌套表格、图文混排的 PDF,转换时文本流顺序混乱(如左栏文字跑到右栏下方),与 Word 段落标记冲突。
- 技术瓶颈:矢量图形(如流程图、公式)与文本层的坐标映射错误,导致符号重叠或错位。
二、6 步排查法:从简单到专业的修复路径
第一步:基础检查(5 分钟快速修复)
1、替换字体法(适用字体缺失)- 用 Word 打开乱码文档,全选内容(Ctrl+A),右键「字体」,尝试切换思源黑体、华文宋体等多语言支持字体。
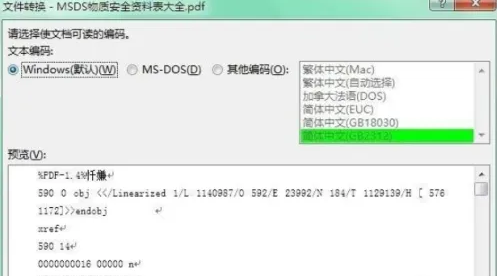
- 高级操作:点击「字体」→「替换字体」,将「缺失字体」映射到本地已安装字体(如将「FZCuYinSong」映射为「微软雅黑」)。
2、另存为纯文本(初步过滤格式错误)- 用记事本打开乱码 Word 文件(需先另存为「纯文本.txt」),再复制回 Word,可清除大部分格式干扰码。
第二步:专业工具深度转换(成功率提升 40%)
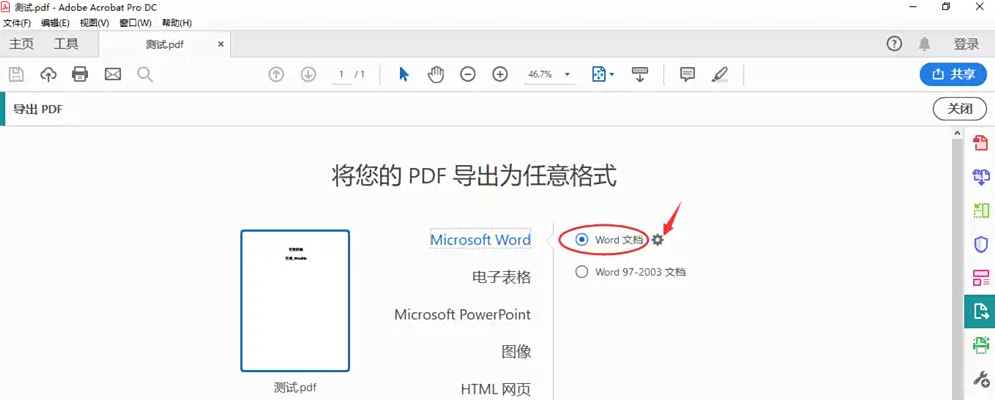
1、Adobe Acrobat 原生转换(推荐企业用户)
操作步骤:
- 用 Acrobat 打开 PDF,点击「转换为 Word」→「自定义转换」
- 勾选「保留字体」「识别扫描文本(OCR)」(针对扫描件)
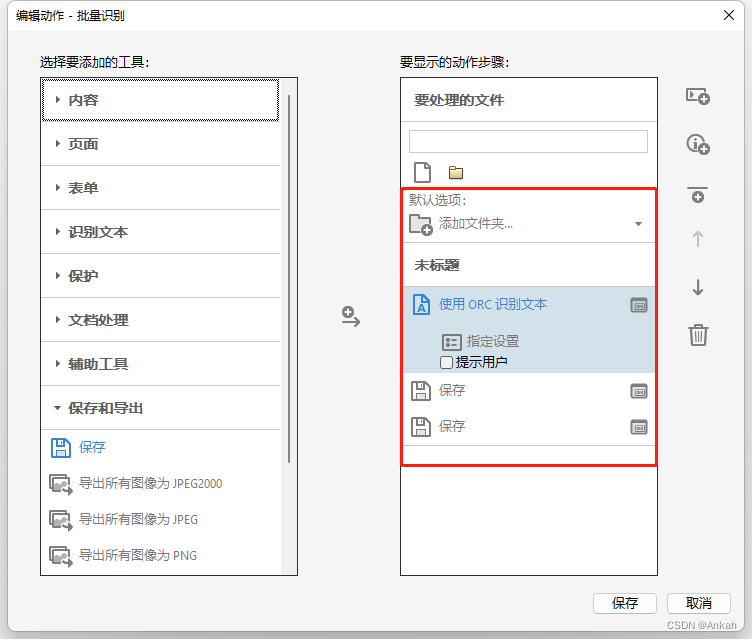
- 高级设置:选择「中国(GB)」区域设置,避免编码误判
- 优势:支持 14 种亚洲语言深度解析,字体映射准确率达 92%。
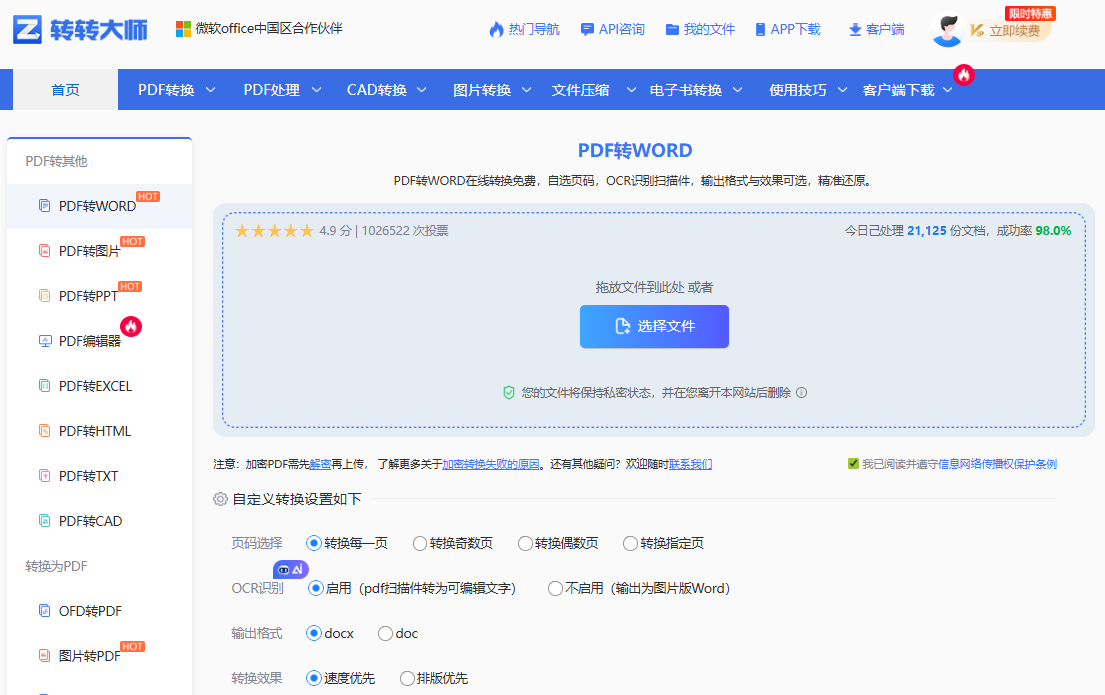
2、SmallPDF 智能修复(适合轻度用户)在线操作:
- 上传 PDF 后,在转换选项中开启「修复乱码」开关(需订阅版),工具会自动检测缺失字体并启用云端字体库补全。
第三步:OCR 技术处理扫描件(针对图片型 PDF)
1、转转大师pdf转换器 OCR 功能操作步骤:- 「勾选图片转文字」
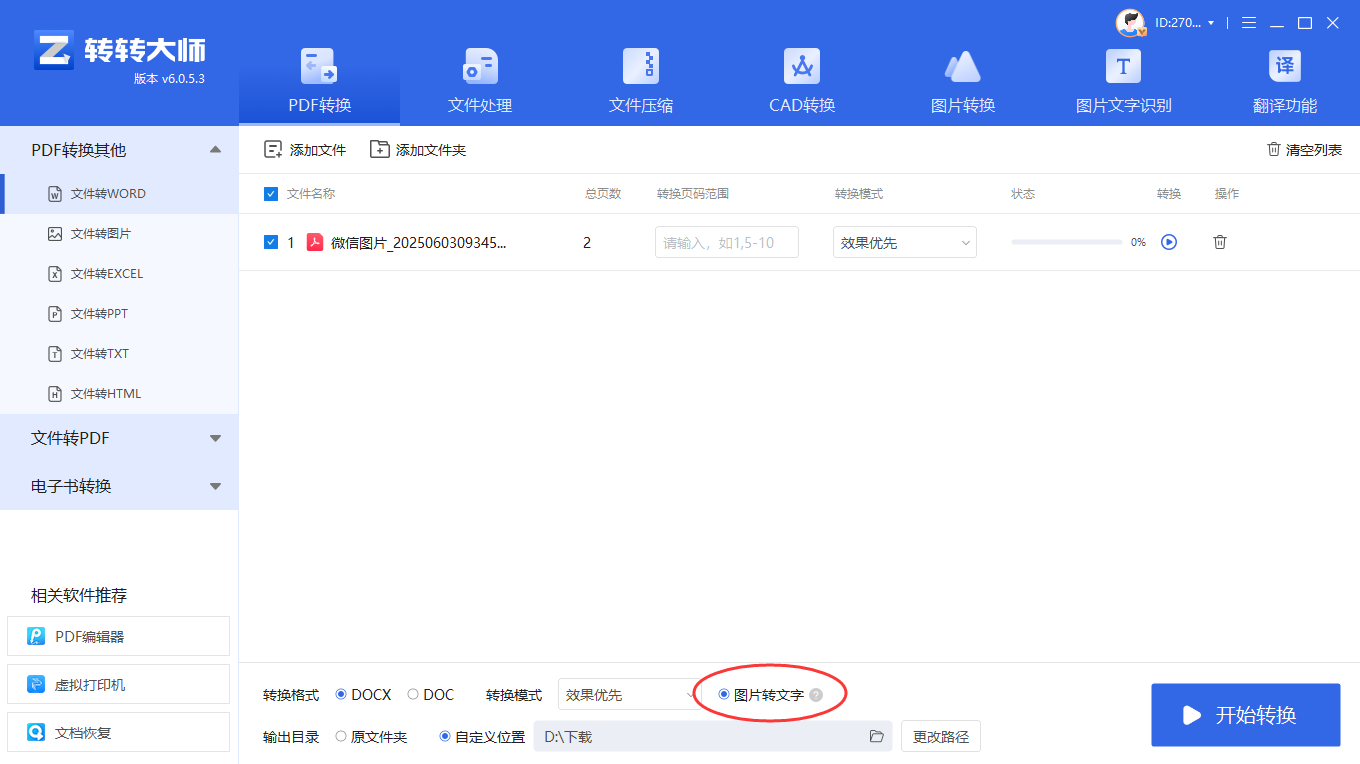
- 识别后再转 Word,乱码率从 70% 降至 15% 以下。
2、ABBYY FineReader 专业解析- 优势:支持 192 种语言混合识别,对倾斜文本、低对比度图片的处理能力优于普通工具,转换后可编辑率达 95%。
第四步:编码转换与格式重构(技术型用户)
1、Notepad++ 编码修复- 用 Notepad++ 打开乱码 Word 的 XML 源文件(Word 另存为「Word XML 文档」),

- 点击「编码」→「转为 UTF-8 无 BOM 格式」,再重新导入 Word。
2、分段转换法- 将多章节 PDF 按页码拆分(用 转转大师「拆分 PDF」功能),逐章节转换后再合并,避免复杂格式一次性解析失败。
第五步:代码级修复(进阶方案)
1、Python 脚本处理(需基础编程)使用 PyPDF2 和 python-docx 库:

- 关键:通过font_path参数强制指定本地字体,解决字体缺失问题。
2、正则表达式清洗乱码
- 在 Word 中按Ctrl+H打开替换功能,输入正则表达式[^\x00-\x7F](匹配所有非 ASCII 字符),替换为空,清除非法字符。
第六步:终极方案 —— 人工校对(确保 100% 准确)
制作「乱码排查表」,逐页对比 PDF 与 Word:
页码 | 乱码类型 | 原因分析 | 修复操作 | 耗时 |
3 | 方块字符 | 思源黑体缺失 | 替换为华文黑体 | 1min |
7 | 符号错位 | 表格解析错误 | 手动调整表格行列 | 3min |
三、预防指南:3 招避免未来乱码
1. 源文件预处理
- 嵌入字体:用 Acrobat「文档属性」
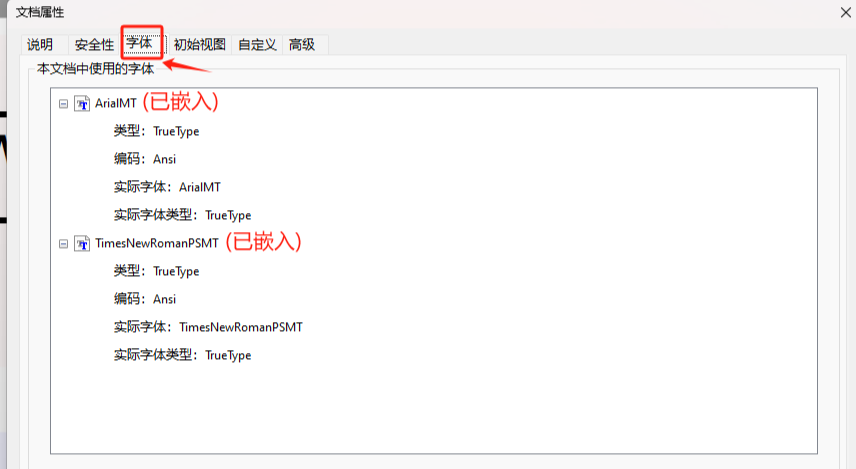
- 「字体」,检查是否嵌入所有字体(状态显示「已嵌入子集」),未嵌入的点击「嵌入」。
- 扫描件优化:用 CamScanner 扫描时选择「文档模式」,生成「可搜索 PDF」而非纯图片 PDF。
2. 工具选择策略
- 优先企业级工具:Adobe Acrobat(商业场景)、福昕高级 PDF 编辑器(性价比之选),避免使用无资质的免费在线工具(乱码率超 40%)。
- 转换前预览:多数工具支持「转换预览」功能,重点检查标题、表格、公式区域是否正常。
3. 版本兼容性管理
- 避免跨版本强转:PDF 2.0 格式文件转 Word 2003 版,乱码风险增加 3 倍,建议统一使用 Office 2016 + 或 PDF/A 标准文件。
- 保留原文件:转换前复制 PDF 副本,防止误操作导致源文件损坏。
四、效率工具包(快速取用)
工具类型 | 推荐工具 | 核心优势 | 乱码修复功能 | 下载 / 链接 |
桌面端 | Adobe Acrobat | 全功能支持 | 字体映射、OCR 深度识别 | 官网 |
在线工具 | SmallPDF | 无需安装 | 智能乱码修复开关 | 官网 |
OCR 工具 | ABBYY FineReader | 高精度识别 | 多语言混合文本处理 | 官网 |
编程接口 | pdf2docx | 自定义字体 | 代码级字体指定 | pip install pdf2docx |
总结
以上就是PDF转Word乱码怎么办的全部介绍了,PDF 转 Word 乱码本质是「格式语义损耗」问题,通过「技术排查 + 工具组合 + 人工校验」的三层体系,可系统性解决 95% 以上的乱码场景。建议优先使用专业工具完成 80% 的基础修复,再针对剩余复杂问题(如手绘公式、特殊符号)进行人工优化,既能保证效率,又能确保文档可用性。下次遇到乱码时,按本文步骤逐步排查,再也不用对着满屏乱码发愁了!
 【官方直达】如果您急需处理文档,可直接点击:PDF转WORD在线转换免费入口>>
【官方直达】如果您急需处理文档,可直接点击:PDF转WORD在线转换免费入口>> 微软office中国区合作伙伴
微软office中国区合作伙伴 热门导航
热门导航 API咨询
API咨询 APP下载
APP下载

 客户端
客户端 PDF转换器下载
PDF转换器下载 图片转文字
图片转文字 TIF压缩
TIF压缩 WMF压缩
WMF压缩 JPEG压缩
JPEG压缩 证件照压缩
证件照压缩 压缩指定大小
压缩指定大小 BMP压缩
BMP压缩 GIF压缩
GIF压缩 PNG压缩
PNG压缩 JPG压缩
JPG压缩 MOBI转PDF
MOBI转PDF EPUB转PDF
EPUB转PDF TIF转PDF
TIF转PDF EPUB转TXT
EPUB转TXT WORD转TXT
WORD转TXT EXCEL转TXT
EXCEL转TXT MOBI转TXT
MOBI转TXT TXT转MOBI
TXT转MOBI AZW3转TXT
AZW3转TXT EXCEL转Word
EXCEL转Word TXT转Word
TXT转Word EPUB转Word
EPUB转Word
 PDF转换器
PDF转换器  OCR文字识别
OCR文字识别 数据恢复软件
数据恢复软件 PDF阅读器
PDF阅读器 PDF编辑器
PDF编辑器 微信
微信 微信
微信 QQ
QQ QQ
QQ QQ空间
QQ空间 QQ空间
QQ空间 微博
微博 微博
微博 pdf怎么转换成word乱码怎么办
pdf怎么转换成word乱码怎么办 免费下载
免费下载


















 客服热线:17306009113
客服热线:17306009113
