发布时间:2026-07-04 09:47:28 来源:转转大师 阅读量:3445
跳过文章,直接PDF转EXCEL在线转换免费>>本文介绍了四种将PDF转换为Excel表格的方法:手动复制粘贴法、在线转换工具法、专业桌面软件法和编程脚本法。手动方法适用于小数据量,但格式易错;在线工具便捷但存在隐私风险;专业软件精度高但成本较高;编程方法适合开发者,可实现自动化处理。每种方法均有适用场景、操作步骤及注意事项,强调数据校验的重要性,以确保转换后的准确性。
 【官方直达】如果您急需处理文档,可直接点击:PDF转EXCEL在线转换免费入口>>
【官方直达】如果您急需处理文档,可直接点击:PDF转EXCEL在线转换免费入口>>
在日常办公、财务分析、市场调研或学术研究中,我们经常会遇到一个令人头疼的问题:急需的数据被“锁”在PDF格式的文件里。PDF因其出色的跨平台稳定性和阅读体验而成为文档分发的首选,但其不可直接编辑的特性也成为了数据再利用的最大障碍。将PDF表格转换为可编辑、可计算的Excel工作表,从而进行数据分析、图表制作或进一步处理,是一项至关重要的技能。
那么pdf怎么转换成excel表格呢?本文将深入探讨四种主流且高效的pdf转excel方法,涵盖从简单快捷的在线工具到精准强大的专业软件,乃至面向开发者的编程方案。每种方法都将配以详细的适用场景、 step-by-step 操作步骤和关键注意点,助您根据自身需求选择最佳解决方案,彻底摆脱手动录入数据的低效泥潭。
这是最基础、最无需学习成本的方法,适用于临时性、小批量的简单数据提取任务。
适用场景:
操作步骤:
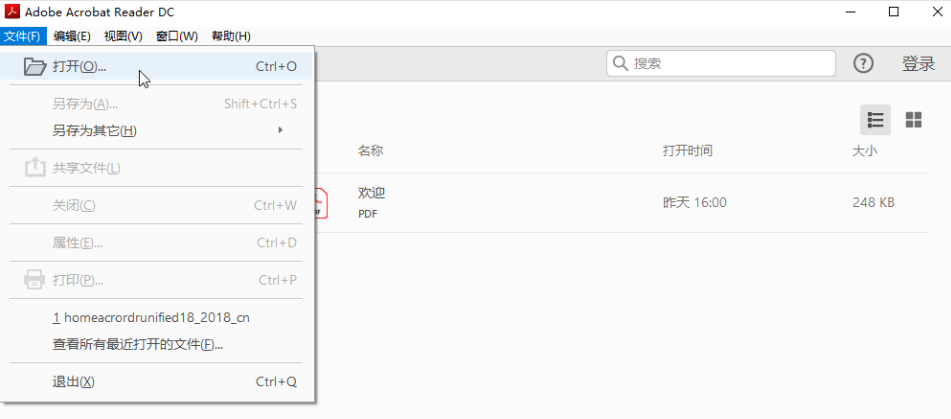

Ctrl + C)。Ctrl + V)。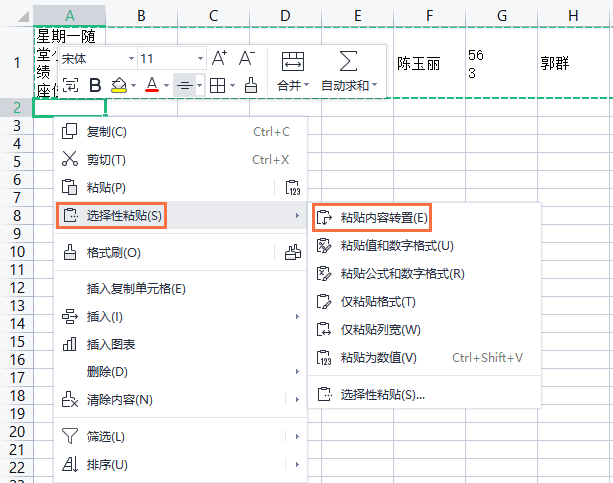
注意点:
在线转换工具是绝大多数普通用户的首选。它们无需安装软件,通过浏览器即可完成转换,在便捷性和效果之间取得了良好平衡。
适用场景:
推荐工具: 转转大师在线工具
操作步骤:
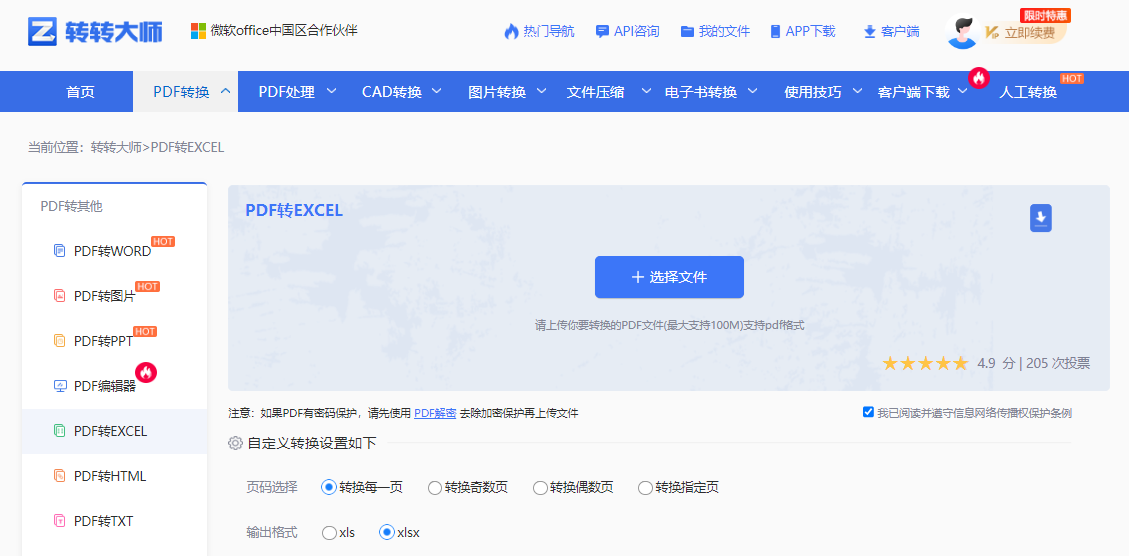
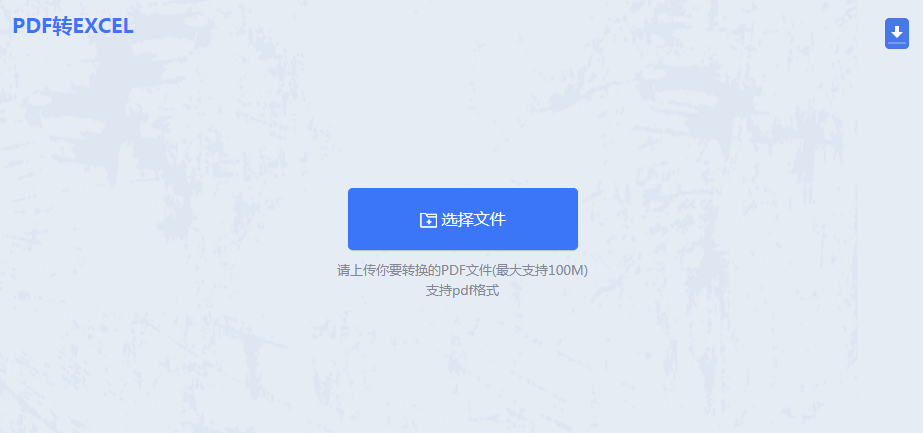
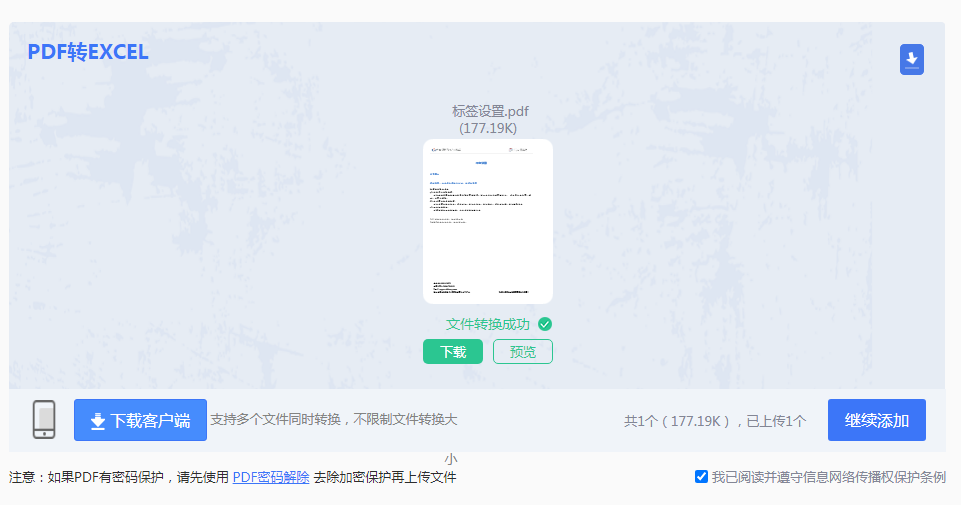
注意点:
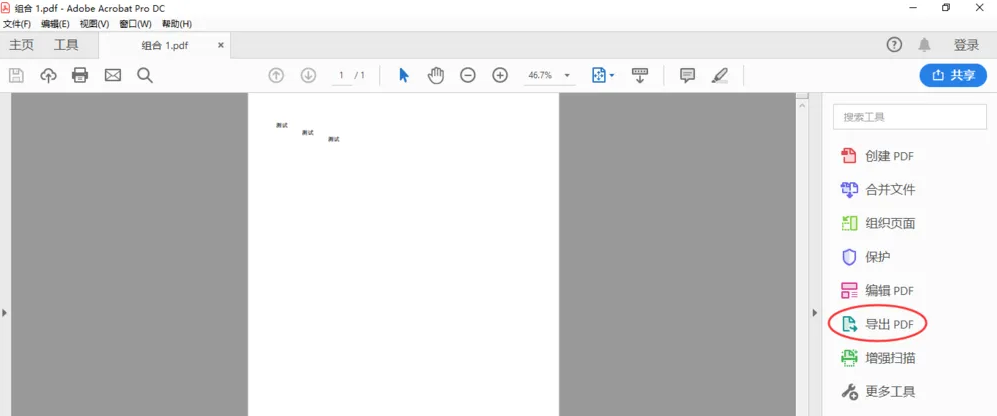
对于需要频繁、批量处理复杂PDF表格,且对转换准确率和格式保真度有极高要求的用户,专业桌面软件是不二之选。
适用场景:
推荐软件: Adobe Acrobat Pro DC(行业黄金标准)、ABBYY FineReader PDF(OCR之王)、Wondershare PDFelement(性价比之选)。
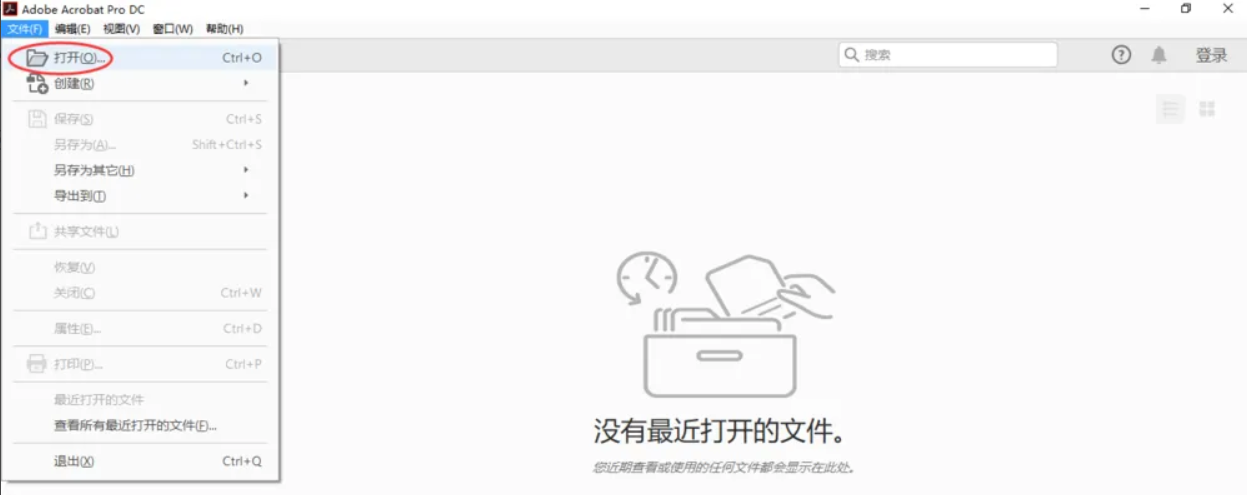
操作步骤(以Adobe Acrobat Pro DC为例):
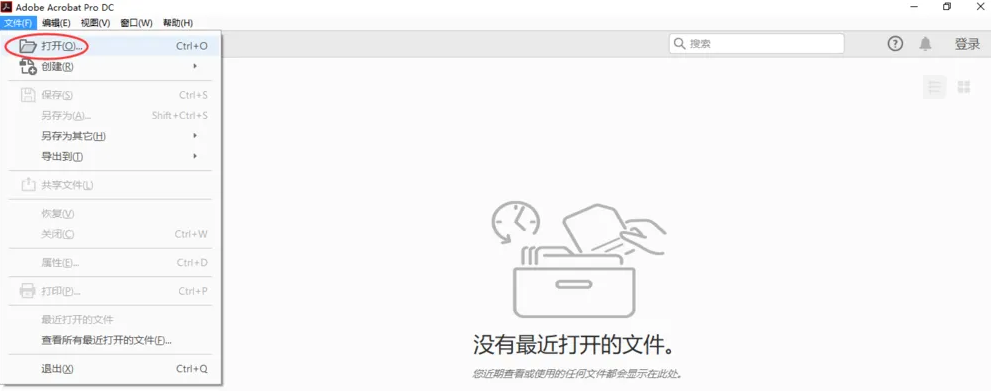
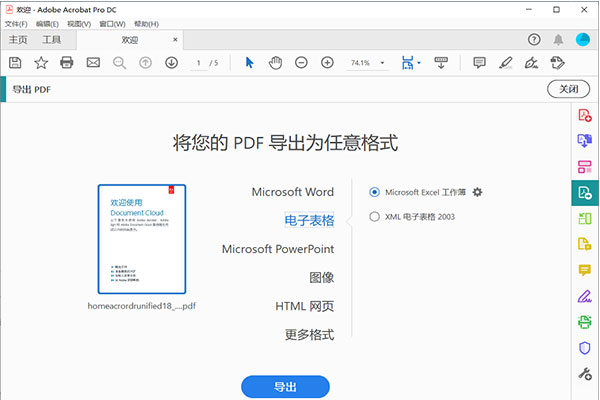
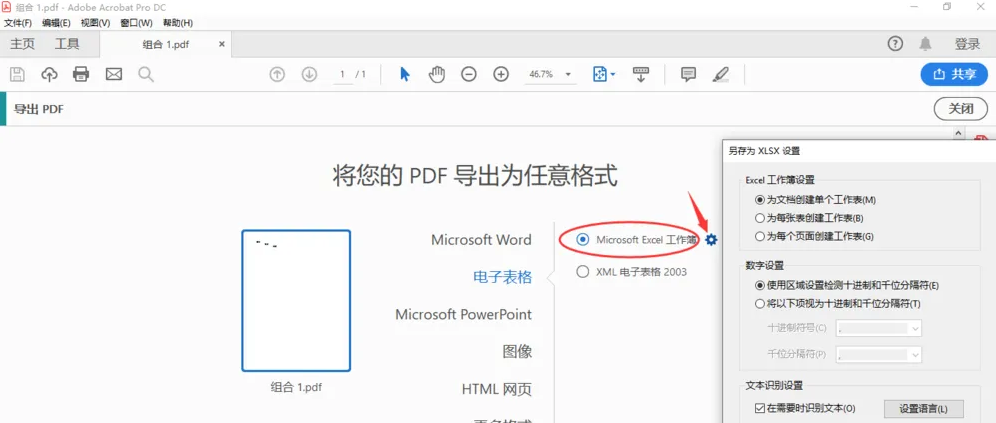
注意点:
对于程序员、数据分析师或IT管理员,通过编写脚本(如Python)来实现PDF到Excel的转换,可以实现最大程度的自动化和定制化。
适用场景:
核心技术库(Python为例):
tabula-py:专门用于从PDF中提取表格数据,底层是Java库tabula-java,效果极佳。camelot-py:另一个强大的表格提取库,能处理 lattice(有线)和 stream(无线)表格。PyMuPDF (fitz):一个更底层的PDF操作库,功能强大但使用更复杂。openpyxl 或 pandas:用于将提取的数据写入Excel文件。简化操作步骤示例(使用Python + tabula-py):
pip install tabula-py openpyxl pandas。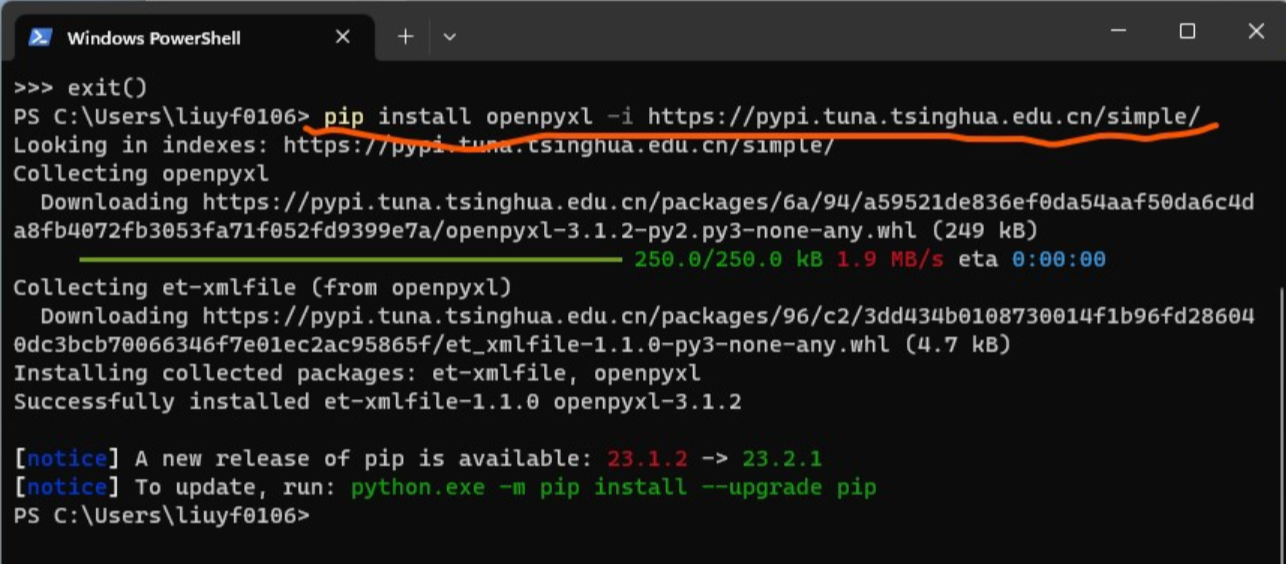
2、编写脚本:
import tabula
import pandas as pd
# 指定PDF文件路径
pdf_path = "input.pdf"
# 使用tabula读取PDF中的所有表格
# pages='all' 表示提取所有页, multiple_tables=True 表示一页可能有多个表
dfs = tabula.read_pdf(pdf_path, pages='all', multiple_tables=True)
# 创建一个ExcelWriter对象,用于写入多个Sheet
with pd.ExcelWriter('output.xlsx', engine='openpyxl') as writer:
for i, df in enumerate(dfs):
# 将每个提取的DataFrame写入Excel的一个单独的工作表
df.to_excel(writer, sheet_name=f'Table_{i+1}', index=False)
print("转换完成!")python your_script_name.py。output.xlsx 文件。注意点:
tabula 等库主要处理原生文本PDF,对扫描件图片的支持需要结合其他OCR库(如Tesseract),复杂度急剧上升。| 方法 | 优点 | 缺点 | 最佳适用场景 |
|---|---|---|---|
| 手动复制 | 无需任何工具和网络,立即可用 | 效率极低,易出错,格式全无 | 极少量、极简单数据的应急处理 |
| 在线工具 | 方便快捷,无需安装,跨平台 | 有文件大小和次数限制 | 处理非敏感、中小批量、非扫描件PDF |
| 专业软件 | 精度高,功能强,支持OCR,可批量,离线安全 | 成本高,占用资源,需安装 | 频繁、大批量处理复杂/扫描件PDF,敏感数据 |
| 编程脚本 | 自动化,可定制,适合集成,处理海量数据 | 技术门槛高,调试复杂 | 程序员、数据分析师的大规模自动化任务 |
通用黄金法则: 无论选择哪种方法,转换后的数据校验都是最重要且不可省略的一步。软件和算法并非万能,特别是面对人类手工制作的、格式千奇百怪的表格时。花几分钟时间快速比对原PDF和生成的Excel,可以避免因数据错误导致的后续分析功亏一篑。
以上就是pdf怎么转换成excel表格的全部介绍了,希望这篇详尽指南能成为您处理PDF转Excel问题的强大参考,让您从此在面对此类任务时都能游刃有余,高效准确地释放数据的真正价值。
【PDF转Excel数据提取4法:识别率从60%到95%,差别在OCR设置!】相关推荐文章: 返回转转大师首页>>
我们期待您的意见和建议:
 微软office中国区合作伙伴
微软office中国区合作伙伴 热门导航
热门导航 API咨询
API咨询 APP下载
APP下载

 客户端
客户端 PDF转换器下载
PDF转换器下载 图片转文字
图片转文字 TIF压缩
TIF压缩 WMF压缩
WMF压缩 JPEG压缩
JPEG压缩 证件照压缩
证件照压缩 压缩指定大小
压缩指定大小 BMP压缩
BMP压缩 GIF压缩
GIF压缩 PNG压缩
PNG压缩 JPG压缩
JPG压缩 MOBI转PDF
MOBI转PDF EPUB转PDF
EPUB转PDF TIF转PDF
TIF转PDF EPUB转TXT
EPUB转TXT WORD转TXT
WORD转TXT EXCEL转TXT
EXCEL转TXT MOBI转TXT
MOBI转TXT TXT转MOBI
TXT转MOBI AZW3转TXT
AZW3转TXT EXCEL转Word
EXCEL转Word TXT转Word
TXT转Word EPUB转Word
EPUB转Word
 PDF转换器
PDF转换器  OCR文字识别
OCR文字识别 数据恢复软件
数据恢复软件 PDF阅读器
PDF阅读器 PDF编辑器
PDF编辑器 微信
微信 微信
微信 QQ
QQ QQ
QQ QQ空间
QQ空间 QQ空间
QQ空间 微博
微博 微博
微博 pdf表格转excel
pdf表格转excel 免费下载
免费下载












 客服热线:17306009113
客服热线:17306009113
