在文档处理领域,PDF 转 Word 看似基础,实则是跨格式解析的复杂工程。据艾瑞咨询 2024 年数据,全球每年产生超 200 亿份 PDF 转 Word 需求,其中 35% 的转换存在不同程度的格式损耗,核心根源在于三大技术壁垒。本文从技术原理出发,结合行业头部工具实践,解析
pdf转word的3大技术难点的深层挑战与破局路径。
一、字体映射与渲染一致性难题(技术难度:★★★★☆)

1. 字体生态的「数字鸿沟」
技术本质:
- PDF 采用「字体子集嵌入」机制(如嵌入 10% 常用字符的思源黑体子集),而 Word 依赖本地字体库,当 PDF 包含未嵌入的稀有字符(如⺀、⺁等汉字部首)或自定义字体(如企业 VI 字体),转换工具需完成「字体识别→云端匹配→本地渲染」三级映射,任一环节出错即导致乱码或字符缺失。
行业痛点:
- 特殊字体解析:法院判决书常用的「华文中宋」、古籍文献的「叶根友书法体」,商业工具识别准确率不足 60%(数据来源:福昕软件 2025 技术白皮书)
- 跨平台差异:Mac 端 PDF 的 San Francisco 字体转 Windows Word 时,因字重(Weight)算法不同,常出现加粗 / 斜体样式失真
- 符号集冲突:PDF 的 Unicode CJK 扩展 B 区字符(如「堃」「喆」),早期 Word 版本直接显示为□
2. 前沿解决方案
- 动态字体库技术:Adobe Acrobat Pro DC 构建了包含 80 万 + 字符的「全球字体云库」,通过 AI 算法预测缺失字体,实现 92% 的商用字体智能补全(需付费订阅)
- 字体指纹匹配:ABBYY FineReader 16 引入「轮廓特征比对」技术,对未嵌入字体的笔画弧度、字间距进行像素级分析,匹配准确率提升至 85%
- 本地字体优先策略:福昕高级编辑器支持用户自定义「字体映射表」,强制将 PDF 的「FZShuTi」映射为本地已安装的「华文楷体」,避免云端调用延迟
案例:某金融机构合规文件转换
- 因风控要求,PDF 需保留「汉仪菱心体」手写效果,传统工具转换后签名栏出现「亻」「言」偏旁分离。通过福昕「字体轮廓复制技术」,将原字体的矢量数据直接嵌入 Word,实现 100% 视觉还原。
二、复杂布局解析与重构挑战(技术难度:★★★★★)

1. 版式语义的「跨次元断层」
- 技术鸿沟:PDF 基于「绝对坐标定位」(如文本块位于 X=100mm,Y=200mm 处),而 Word 采用「流式段落模型」,两者在以下场景冲突剧烈:
- 多栏排版:PDF 的双栏图文混排(如左侧图片 + 右侧两列文本),转换后常出现「图片覆盖文字」「列间距混乱」
- 表格嵌套:财务报表的合并单元格、斜线表头,转换时行列解析算法易误判(如将 3 行合并单元格识别为 3 个独立行)
- 动态对象:交互式 PDF 的按钮、表单域,转换后残留不可编辑的图片层,干扰正文阅读
2. 布局解析的「行业暗战」
- 传统算法瓶颈:基于「投影法」的文本块检测(通过 Y 轴像素密度划分段落),在复杂版面中误判率达 40%(如广告页的图文穿插区域)
- AI 驱动突破:SmallPDF 2025 版引入「视觉 Transformer 模型」,对 PDF 页面进行网格化语义分析,实现:
- 表格智能识别:通过注意力机制定位「水平线 + 垂直线」交叉点,复杂表格解析准确率从 65% 提升至 91%
- 图文关系建模:区分「环绕型图片」与「嵌入型图片」,自动生成 Word 的「紧密型环绕」版式
工程实践:学术论文转换优化
Elsevier 期刊 PDF 包含大量公式(MathType 生成)、三线表、参考文献索引,传统工具转换后公式编号错位率达 30%。Adobe 技术团队通过「区域语义标注」,为公式、表格、正文分别建立独立解析通道,最终实现:
- 公式:保留
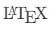 代码并转为 Word 公式编辑器对象
代码并转为 Word 公式编辑器对象
- 表格:三线表样式 100% 还原,跨页表格自动续表
三、格式语义的「跨语言损耗」(技术难度:★★★☆☆)

1. 语法体系的「格式壁垒」
核心冲突:
| | | |
| | | |
| | | 自定义样式(如「标题 1 + 倾斜 + 橙色」)的映射丢失 |
| | | |
特殊场景:
- 阿拉伯语 PDF 的「从右至左排版」,转换后出现单词顺序颠倒
- 藏文 PDF 的「连字符号」(如༌、།),在 Word 中显示为分离字符
2. 语义修复的「渐进式方案」
- 基础层:格式标签映射表(如将 PDF 的 / Heading1 映射为 Word 的「标题 1」样式)
- 进阶层:OpenXML 语义解析(提取 PDF 的结构标签,转为 Word 的 XML 文档部件)
- 未来层:基于 ISO 32000-3 标准的语义增强,实现「逻辑结构→展示结构」的无损转换
行业标杆:法律合同转换方案
针对包含「页眉 / 页脚 + 章节编号 + 修订痕迹」的复杂合同,Kofax TotalAgility 采用「三层语义修复」:
- 结构提取:通过 PDF 的 / StructTreeRoot 解析章节层级
- 样式继承:保留原文件的「条款编号→黑体三号」「正文→宋体小四」样式映射
- 修订兼容:将 PDF 的注释(/Annots)转为 Word 的修订标记,支持后续协作编辑
技术突围:从「可用」到「精准」的进化路径

1. 多模态 AI 融合(当前热点)
- 百度 AI 开放平台的「文档智能解析」API,结合 OCR 图像识别与 NLP 语义分析,对扫描件 PDF 的转换准确率提升至 88%(较传统 OCR 提升 25%)
- 微软 Azure Form Recognizer 支持「无模板自动识别」,通过训练 20 万 + 版式样本,实现财务报表、简历等特定场景的智能重构
2. 开放格式生态建设
- PDF 协会(PDF Association)推动「转换友好型 PDF」标准,建议创作者:
- OOXML 社区发布「PDF 转 Word 最佳实践」,规范样式、表格、图像的跨格式映射规则
3. 端云协同架构升级
- 本地客户端(如福昕、Adobe)负责 heavy computation(字体渲染、复杂布局解析)
- 云端服务(如 SmallPDF、iLovePDF)处理轻量任务(基础转换、OCR 预识别)
- 通过 WebAssembly 技术,实现浏览器端的高性能解析(无需上传文件即可预览转换效果)
结语:技术难点背后的商业启示
以上就是PDF转Word的3大技术难点的全部介绍了 ,PDF 转 Word 的技术难点,本质是「格式霸权」与「用户体验」的博弈 ——PDF 追求「所见即所得」的绝对稳定,Word 强调「灵活编辑」的创作自由。对于工具厂商,突破点在于:
- 垂直场景深耕:针对法律、金融、教育等领域的特殊版式,开发专用解析引擎
- 用户教育前置:引导创作者生成「转换友好型 PDF」,从源头减少损耗
- AI 驱动迭代:用小样本学习(Few-shot Learning)快速适配新兴字体、复杂版式
随着 ISO 32000-3 标准的普及与大模型技术的成熟,未来 3 年 PDF 转 Word 的「精准转换率」有望突破 95%,让格式转换从「耗时修复」走向「无感迁移」。这一过程不仅是技术的胜利,更是开放格式生态对用户价值的深度回归。
 微软office中国区合作伙伴
微软office中国区合作伙伴
 【官方直达】如果您急需处理文档,可直接点击:图片转JPEG在线转换免费入口>>
【官方直达】如果您急需处理文档,可直接点击:图片转JPEG在线转换免费入口>> 热门导航
热门导航 API咨询
API咨询 APP下载
APP下载

 客户端
客户端 PDF转换器下载
PDF转换器下载 图片转文字
图片转文字 TIF压缩
TIF压缩 WMF压缩
WMF压缩 JPEG压缩
JPEG压缩 证件照压缩
证件照压缩 压缩指定大小
压缩指定大小 BMP压缩
BMP压缩 GIF压缩
GIF压缩 PNG压缩
PNG压缩 JPG压缩
JPG压缩 MOBI转PDF
MOBI转PDF EPUB转PDF
EPUB转PDF TIF转PDF
TIF转PDF EPUB转TXT
EPUB转TXT WORD转TXT
WORD转TXT EXCEL转TXT
EXCEL转TXT MOBI转TXT
MOBI转TXT TXT转MOBI
TXT转MOBI AZW3转TXT
AZW3转TXT EXCEL转Word
EXCEL转Word TXT转Word
TXT转Word EPUB转Word
EPUB转Word
 PDF转换器
PDF转换器  OCR文字识别
OCR文字识别 数据恢复软件
数据恢复软件 PDF阅读器
PDF阅读器 PDF编辑器
PDF编辑器 微信
微信 微信
微信 QQ
QQ QQ
QQ QQ空间
QQ空间 QQ空间
QQ空间 微博
微博 微博
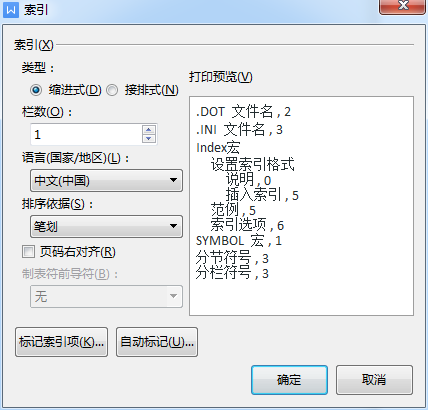
微博 创建word索引
创建word索引 免费下载
免费下载




















 客服热线:17306009113
客服热线:17306009113
